Task Rollouts
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Despite recent progress in general purpose robotics, robot policies still lag far behind basic human capabilities in the real world. Humans constantly interact with the physical world, yet this rich data resource remains largely untapped in robot learning. We propose EgoZero, a minimal system that learns robust manipulation policies from human demonstrations captured with Project Aria smart glasses, and zero robot data. EgoZero enables: (1) extraction of complete, robot-executable actions from in-the-wild, egocentric, human demonstrations, (2) compression of human visual observations into morphology-agnostic state representations, and (3) closed-loop policy learning that generalizes morphologically, spatially, and semantically. We deploy EgoZero policies on a gripper Franka Panda robot and demonstrate zero-shot transfer with 70% success rate over 7 manipulation tasks and only 20 minutes of data collection per task. Our results suggest that in-the-wild human data can serve as a scalable foundation for real-world robot learning — paving the way toward a future of abundant, diverse, and naturalistic training data for robots.
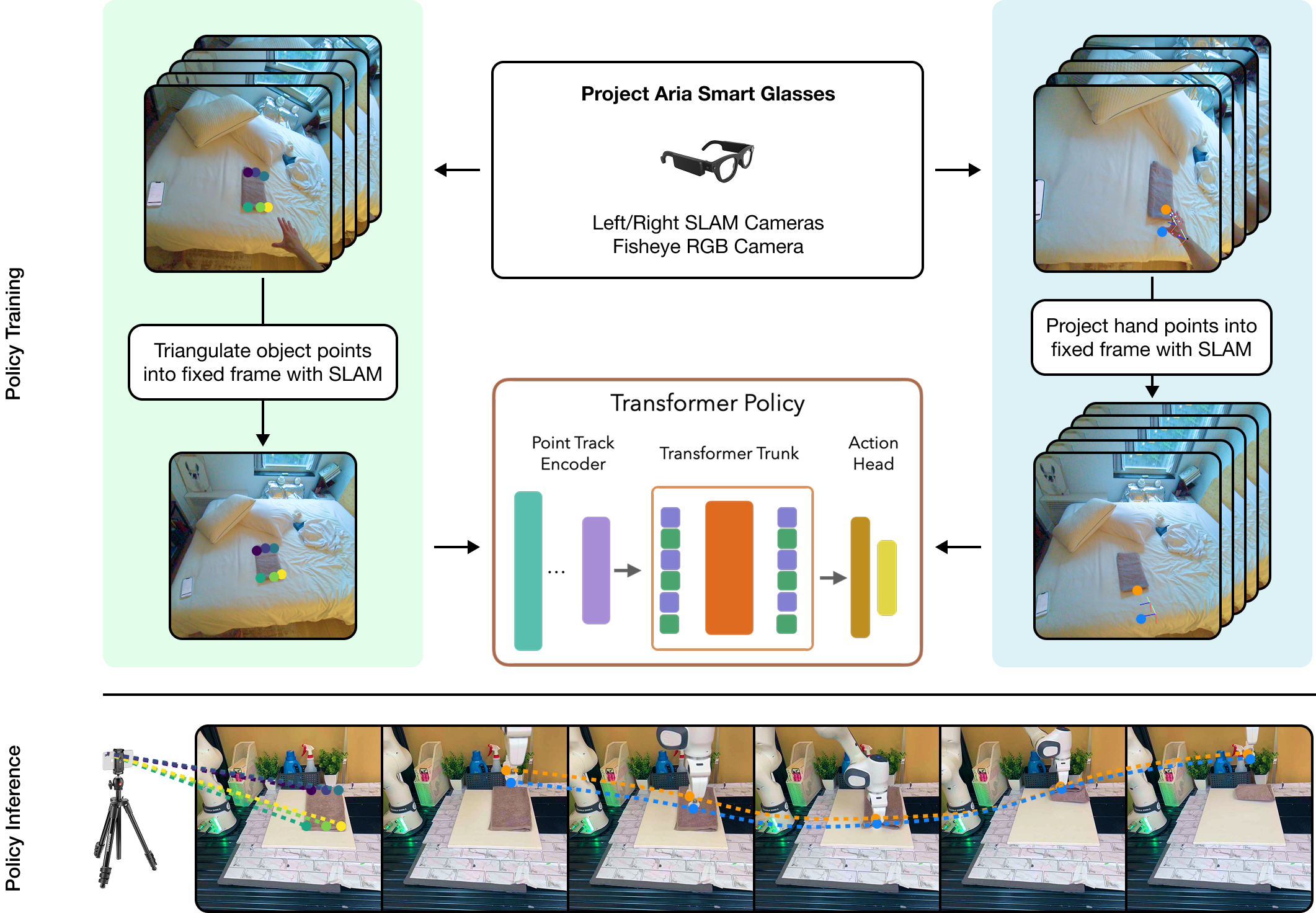
EgoZero trains policies in a unified state-action space defined as egocentric 3D points. Unlike previous methods which leverage multi-camera calibration and depth sensors, EgoZero localizes object points via triangulation over the camera trajectory, and computes action points via Aria MPS hand pose and a hand estimation model. These points supervise a closed-loop Transformer policy, which is rolled out on unprojected points from an iPhone during inference.
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
Human Demonstration
Robot Inference
| Open oven | Pick bread | Sweep broom | Erase board | Sort fruit | Fold towel | Insert book | |
|---|---|---|---|---|---|---|---|
| From vision | 0/15 | 0/15 | 0/15 | 0/15 | 0/15 | 0/15 | 0/15 |
| From affordances | 11/15 | 0/15 | 0/15 | 0/15 | 7/15 | 10/15 | 5/15 |
| EgoZero – 3D augmentations | 0/15 | 0/15 | 0/15 | 0/15 | 0/15 | 0/15 | 0/15 |
| EgoZero – triangulated depth | 0/15 | 0/15 | 0/15 | 11/15 | 0/15 | 0/15 | 0/15 |
| EgoZero | 13/15 | 11/15 | 9/15 | 11/15 | 10/15 | 10/15 | 9/15 |
Success rates for all baselines and ablations. All models were trained on the same 100 demonstrations per task, and evaluated on zero-shot object poses (unseen from training), cameras (iPhone vs Aria), and environment (robot workspace vs in-the-wild). Because of limited prior work in our exact zero-shot in-the-wild setting, we cite the closest work for each baseline.
Human Demonstration
Training Object
Zero-Shot New Object
Human Demonstration
Training Object
Zero-Shot New Object
Human Demonstration
Training Object
Zero-Shot New Object
Human Demonstration
Training Object
Zero-Shot New Object
@misc{liu2025egozerorobotlearningsmart,
title={EgoZero: Robot Learning from Smart Glasses},
author={Vincent Liu and Ademi Adeniji and Haotian Zhan and Raunaq Bhirangi and Pieter Abbeel and Lerrel Pinto},
year={2025},
eprint={2505.20290},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2505.20290},
}